
I
The Moment
We hesitate whispering our secrets to the cloud, guilty trading privacy for convenience.
But we do, because there is joy and beauty in being known and understood by the computer.
With careful architecture, we can feel safe speaking openly around an LLM, safe in the verifiable proof that our data's accessible to us alone.
When we engineer for intimacy, we can bring families together, easily storing and safeguarding our memories for future generations to come.
AI could help preserve the next
millennium of family heritage,...but we hesitate to share our
cherished memories with the cloud.


These objects existed inside multi-generational family environments over the holidays.
II
The Idea
Private at-home intelligence is now in reach. While most of the industry is chasing always-online AI, we've been exploring the alternative.
In Part One of this research, we dove into the case for private AI to explore what will be needed for an air gapped future. When weighing the use cases, families stuck out as both an early adopter and multi-generational beneficiary of local LLMs. Helpful today, crucial tomorrow.
Archiving your family history is a cumbersome process, currently left to the one individual in the family with enough time and conviction to put a book together. LLMs are great at recording unstructured data into a maintainable archive, lowering the barrier to entry for anyone in the family to contribute to the family tree.



The form of the book has endured for centuries. It's timeless in the home and shaped for private reading or collective use.
Family memories belong in the home. With recent AI advancements, this is the first time you're able to build a treasure trove of memories in such a frictionless way for your family. Our heritage and family history is extremely intimate data that many don't want to give to big tech. However there's more utility and longevity of this family information if its archived and browsable digitally.
Previous generations stored family memories physically. Our generation is waking up to the fact that we're losing these memories unless we put systems in place to preserve them.
These memories also need to be embodied, as objects of heritage. They cannot solely live in a phone or a black box home server. We believe in three tenets that these objects must uphold if they wish to be accepted as a new method of archiving. A family intelligence object must be Timeless in its ability to withstand generations, Observable to have an ease of control, and Trustworthy from first glance to the 100th entry into the family tree.

Form follows function. Tenets follow values. The bolded tenets are the ones that felt in harmony.
Families come in all shapes and sizes. They're messy, heartwarming, dysfunctional, inspirational, chosen, bestowed upon us. We considered these many forms of a family to understand how we can design an heirloom that resonates with any family member.
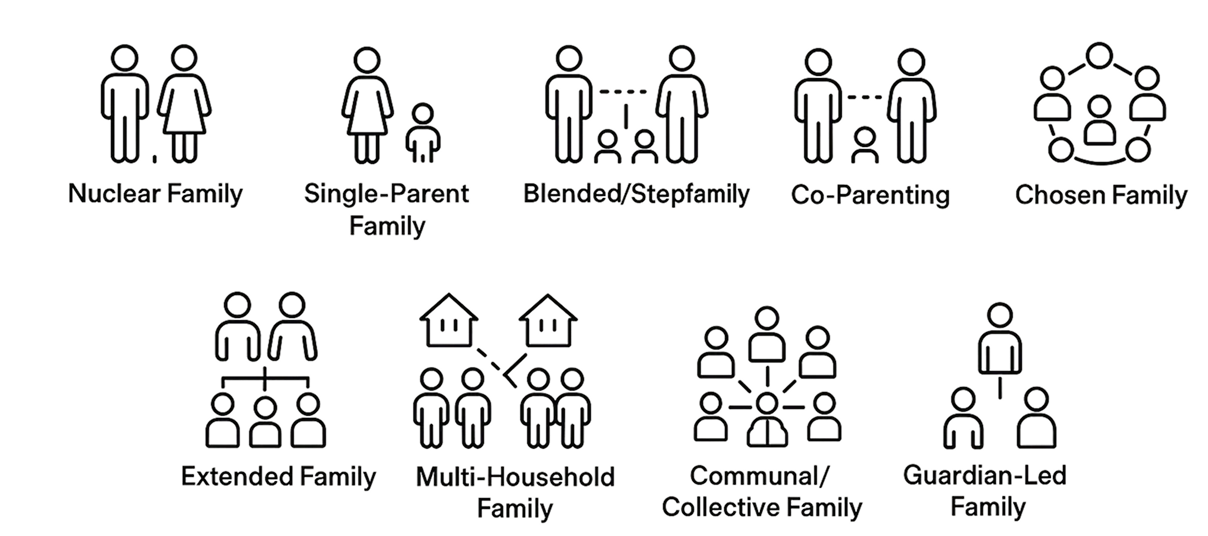
Families don't take a single form, they are a spectrum of structures.
Objects inherently hold memories. Families already embed memories into static objects today, and pass them down their lineage to extend their heritage. A couple types of objects stood out in our research for both private and familial heirlooms.

Objects emerge as long-term memory holders across personal, domestic, and technological forms.
Taking cues from how families archive memories today, we concepted and play-tested different forms that speak to the three tenets of trustworthy, observable, and timeless. They're all around a medium size, able to be quickly thrown in a backpack on the way to Grandma's house, and they all aim to resemble something that already sits in the home today. New objects must meet people halfway to overcome the barrier of entry to change behavior.
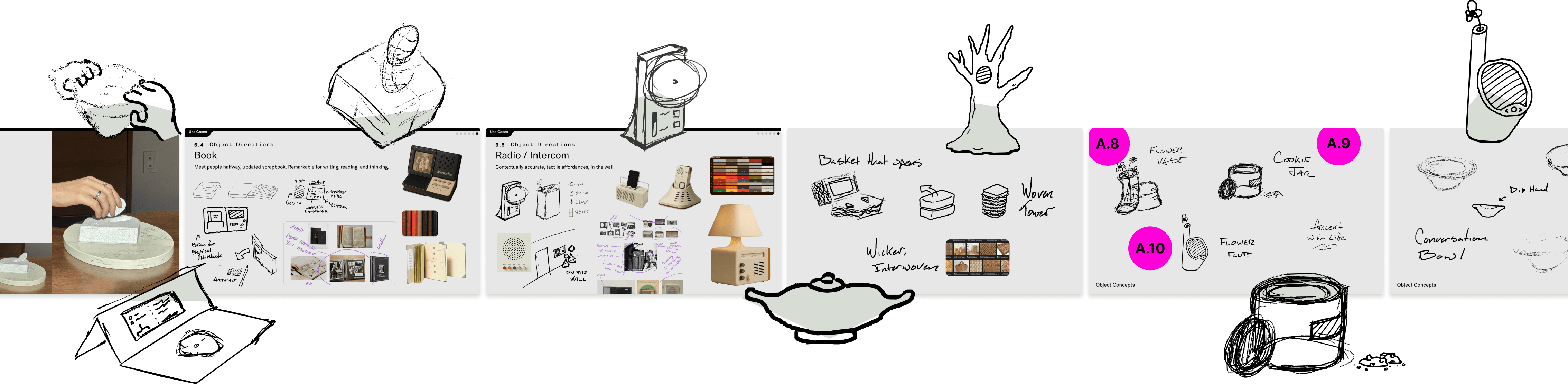
From observation to form, we mapped how everyday objects become memory vessels.
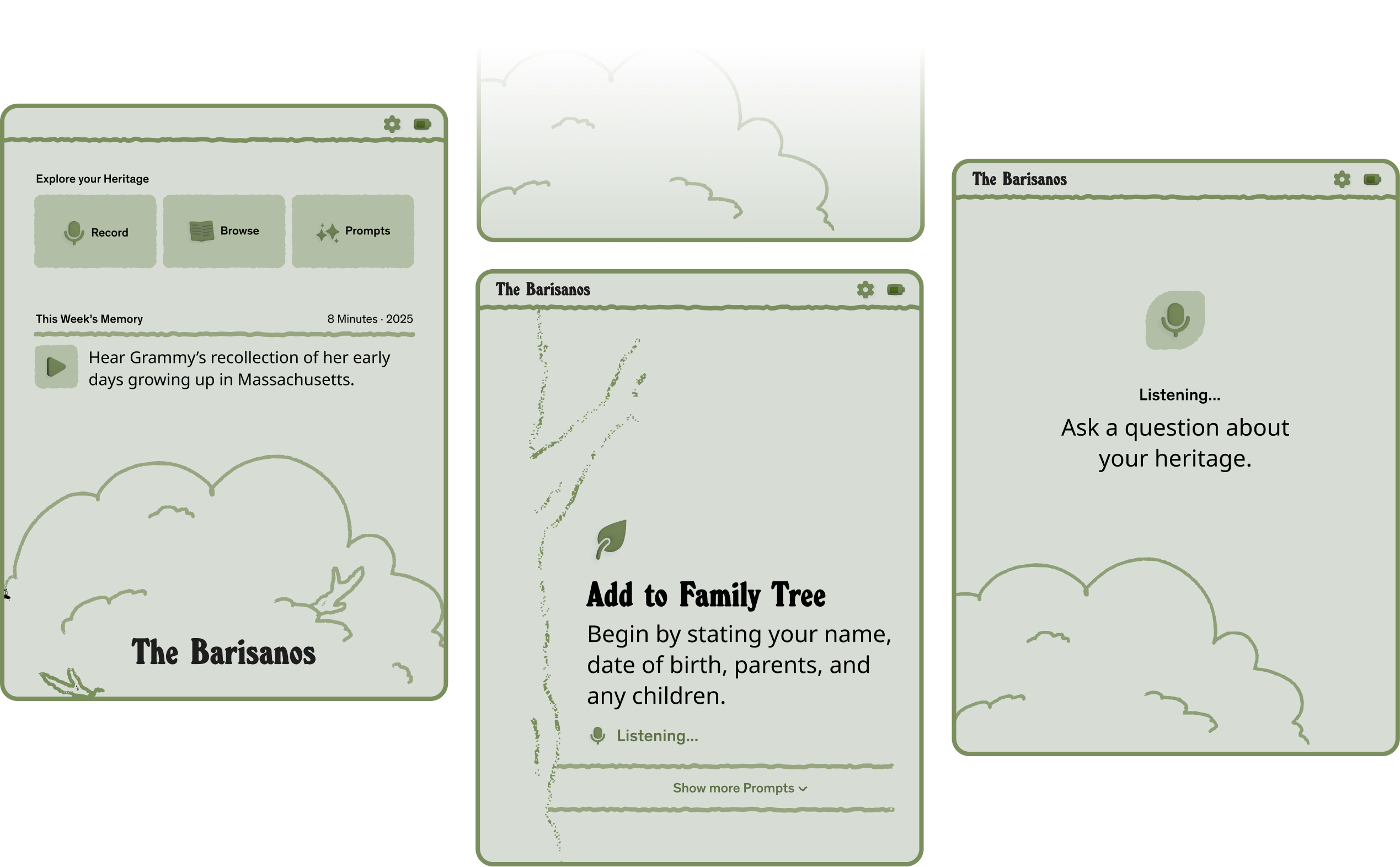
The Leaf
An homage to the family tree, the Family Leaf mimics an alarm clock as a tabletop item and features a removable mic. Stand up the leaf to begin a session or use it as a remote to browse past recordings.





The Radio
The most sentimental of the bunch, the Family Radio is a contextually accurate and historically nostalgic way to browse your family's heritage. It's tactile interfaces keep memories grounded in the home.






The Family Book
A modern update to the scrapbook, which stand the test of time for keeping family memories safe. The Family Book provides an intuitive interface for reading and writing your family's history.





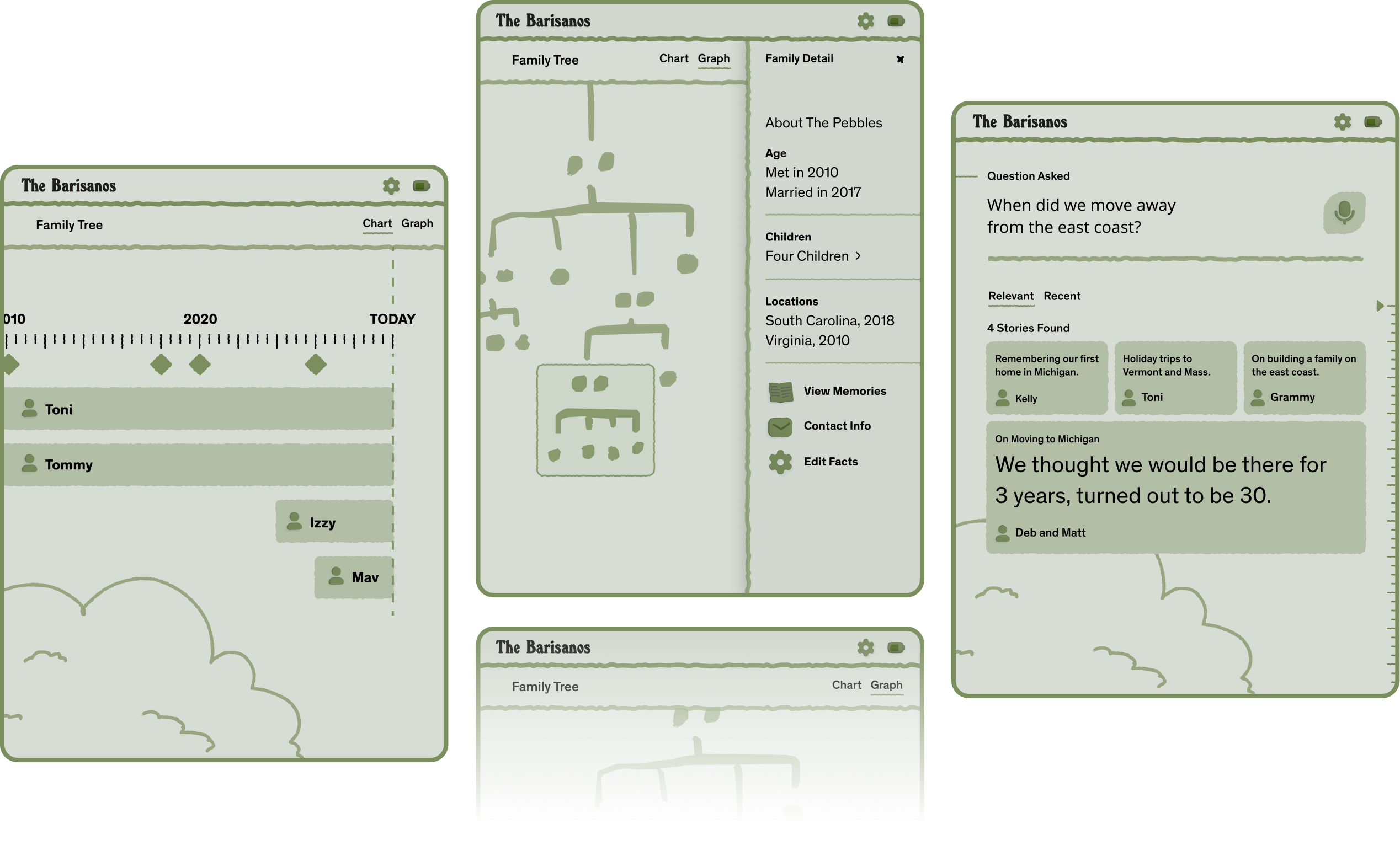
Imagine growing up and being able to spend full days diving into your family tree – your lineage, what your aunt studied in school, where that distant cousin is now, what's your grandma's favorite recipe. Building a system for family intelligence provides easy avenues to this information for all ages. We explored early wireframes that would aide family members looking to learn more.
III
The System
Encouraged by the results of our initial local LLM tests, we filled out the system architecture and ran benchmarks on a wider set of home-ready computers.
The main engineering challenge for building a local LLM system comes down to managing user expectations around performance. While larger cloud-based systems can scale up to enormous amounts of computing power, consumer hardware will need to utilize longer-running AI processes for heavy-duty data processing. These tasks will run on-device in the background and surface results to the user interface when ready.
High-level Architecture
We focused on the main user flow of recording and processing a family conversation for architecting and benchmarking. Audio is one of the many modalities that this object of heritage will support. Let's take a look at our ETL Pipeline, a common pattern to Extract, Transform, and Load data.

This pipeline will serve in real-time to record and store memories as audio, understand them, and load them into an ontological (or categorized) representation. That data will underpin a social graph of nodes such as people, places, and events, and their edges such as relationships and actions.
Step One: Extract and Chunk Audio
With a high degree of resilience, the device will first record chunks of audio directly to storage (e.g. an on-board microSD card) and encrypt it at rest to lower the likelihood of faults like memory overflow, data corruption, or inconsistency in later steps. This is our first step towards an idempotent and reliably consistent processing architecture.
Lastly, to ensure family members feel safe and in control, we'll utilize a physical disconnect switch that allows for pausing of recording during the conversation – perfect for Grandma's dicey side stories.

Step Two: Transform Audio to Recognize Speakers
As chunks are stored safely on disk, the system will pick them up and separate out audio and transcriptions for different speakers. These are often referred to as "Speaker Turns". A couple Python libraries and offline models backed by pyannote-audio and faster-whisper are helpful here.
We store the voices as "voiceprints" so when future recording sessions feature the same speakers they can be logically connected in the social graph. Further, raw transcripts will be stored in the database to be interpreted in the next step.

Step Three: Load into Ontological Vector Database
Finally, as raw transcripts are stored in the database, they'll be picked up and analyzed by the LLM, then compressed and stored for easy RAG retrieval and traversal through a graph database.
For compression, Chain of Density (CoD) is a common prompting technique we can employ to ensure our speaker turns are vectorized at a high degree of detail and predictable length.
For extracting a social graph, we can employ Few-Shot Prompting and strict JSON output to extract social relationships ready for entry into a traditional nodes + edges graph database.

Here is our example system prompt for the curious:
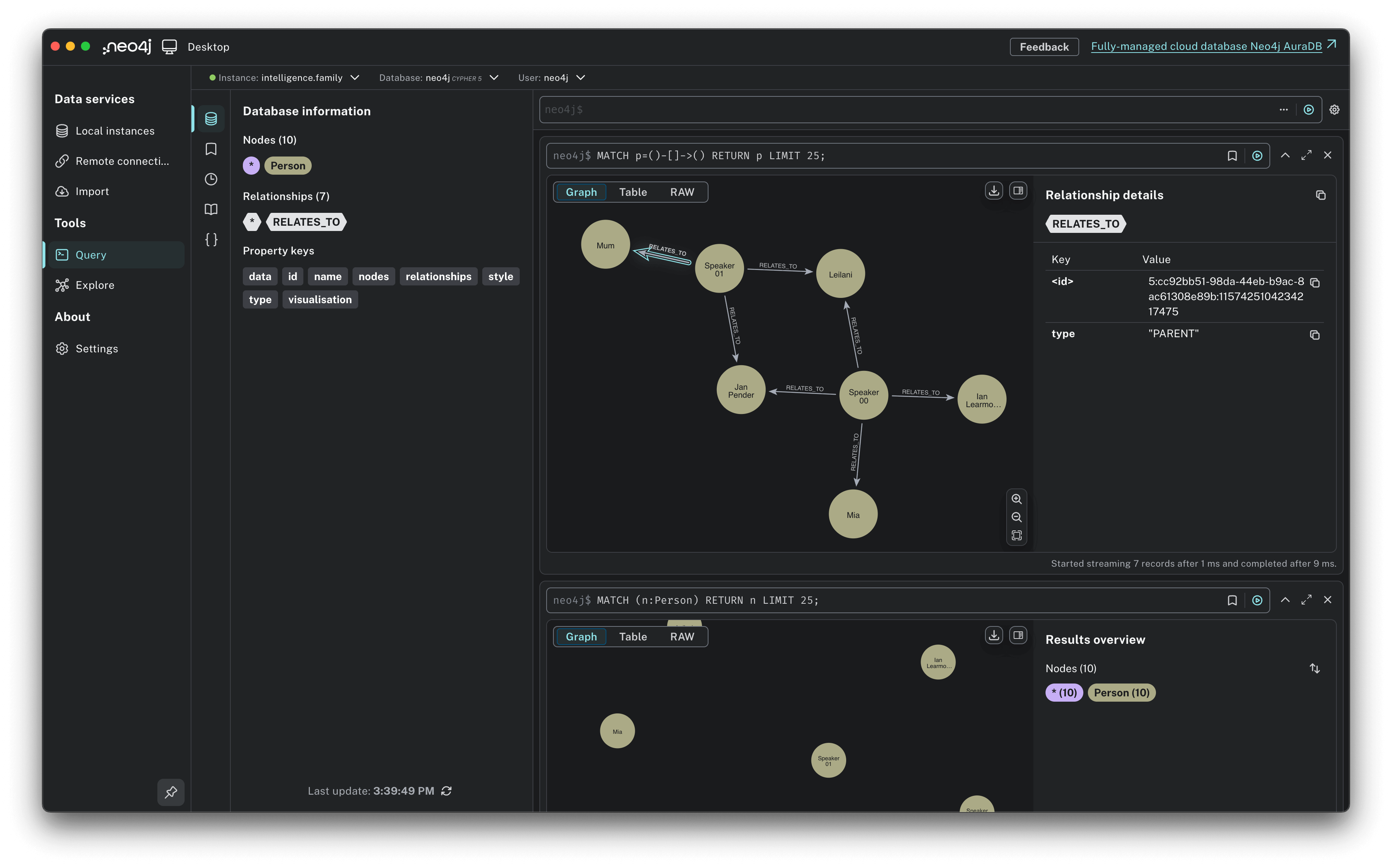
A graph database representation of the relationships of actors in a story, extracted offline by Qwen.
Benchmarking our Chipsets
A key part of our thesis points to the drastic strides in processing speeds that both open source models and consumer-level chipsets have been making every 6 months. Its safe to bet that what might seem resource constrained and inefficient today is likely to be a breeze on hardware and architectures just a year from now.
We wrote a lightweight test harness (view codebase) to asses the feasibility of running this workload on consumer grade hardware. We used this testing framework to run the same benchmark against three best-in-class chipsets. From most to least performant they are:

All benchmarks were run against a cute 3 minute and 42 second story of Hugh's parents explaining how they met in 1985.
“I think we'll be going back to 1984...”
To benchmark the relative performance of these chips, we ran a speaker diarisation process with a local model of pyannote/speaker-diarization-3.1 (Hugging Face) via the pyannote-audio python library.
As expected, the Thor & Orin drastically outperformed the Raspberry Pi 5 16gb, indicating that for the best possible UX we'll need to run the Application Runtime against a GPU enabled system for these processing loads.
For future tests, we'd be interested to run the benchmarks against a smaller size chip to the Pi with an onboard GPU, such as Orange Pi 5, Khadas VIM4, ASUS Tinker Board, or even a Raspberry Pi 5 running an AI-capable HAT like the HAILO SC1785.

While these initial results are encouraging, we look forward to seeing the advancements in these test cases in the coming months.

Intended for use, then for staying
IV
Work with Us
garden3d helps forward-thinking teams explore the edges of local ai, speculative hardware, and product storytelling. We collaborate with brands, labs, and founders to design the next generation of tangible ai experiences. This research is in partnership with usb club, a memory network for preserving what matters.
For partnerships and collaborations, email us at partner@intelligence.family .
.
Subscribe for Updates
This is part four in our ongoing research on local AI. Checkout the previous research on our Substack:
